前回の続き hemus.hatenablog.com
開発
プログラム改修
要点
cron で毎時 0, 15, 30, 45 分に実行するよう変更
sheet1 にデータを蓄積
最終行に追加する手間がかかるため3行目に行追加するよう変更。2行目は数式が埋め込んであるためあえて3行目にしている。
sheet2 に最新のデータを登録
cron
0,15,30,45 * * * * /root/develop/run.sh
python
#!/usr/bin/python3 import sys import datetime import logging # Switch-Botからデータ取得のためのインポート import binascii from bluepy.btle import Scanner, DefaultDelegate, BTLEDisconnectError # GoogleSpreadSheetに書き込むためのインポート import requests import gspread from oauth2client.service_account import ServiceAccountCredentials logging.basicConfig(level=logging.ERROR) # スプレッドシート key_name = '{ jsonファイルを指定 }' book_name = '{ Spreadsheet のファイル名 }' sheet_name = '{ Spredsheet のシート名 }' sheet_name2 = '{ Spredsheet のシート名2 }' # GoogleAPIを通してスプレッドシートに接続 scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive'] credentials = ServiceAccountCredentials.from_json_keyfile_name(key_name, scope) gc = gspread.authorize(credentials) # シートを取得 worksheet = gc.open(book_name).worksheet(sheet_name) worksheet2 = gc.open(book_name).worksheet(sheet_name2) class ScanDelegate(DefaultDelegate): def __init__(self, addr, name, no): DefaultDelegate.__init__(self) self.addr = addr self.name = name self.no = no self.processed_devices = set() # 処理済みのデバイスの初期化 def handleDiscovery(self, dev, isNewDev, isNewData): # アドレスチェック if dev.addr != self.addr: return # 処理済みでないかチェック if dev.addr in self.processed_devices: return # 主処理 for (adtype, desc, value) in dev.getScanData(): # 気温、湿度を読み込んでスプレッドシートに登録 if(adtype == 22): servicedata = binascii.unhexlify(value[4:]) battery = servicedata[2] & 0b01111111 #print(self.name + "," + timestamp + "," + str(battery) + "," + str(temp) + "," + str(humid)) self.writeSpreadsheet(self.name, timestamp, battery, temp, humid, self.no) # 処理したデバイスのアドレスを記録 self.processed_devices.add(dev.addr) return elif(adtype == 255): madata = binascii.unhexlify(value[16:]) humid = madata[4] & 0b01111111 temp = (madata[2] & 0b00001111) / 10 + (madata[3] & 0b01111111) isOverZero=(madata[3]&0b10000000) if not isOverZero: temp = -temp continue else : continue def writeSpreadsheet(self, name, timestamp, battery, temp, humid, no): # 書き込み # 2行目は表示書式、数式などを埋め込むためあえて3行目に追加する worksheet.insert_row([name, timestamp, temp, humid], 3) # 書き込み worksheet2.update_cell(1 + no, 1, name) worksheet2.update_cell(1 + no, 2, timestamp) worksheet2.update_cell(1 + no, 3, battery) worksheet2.update_cell(1 + no, 4, temp) worksheet2.update_cell(1 + no, 5, humid) def scan(addr, name, no): scanner = Scanner().withDelegate(ScanDelegate(addr, name, no)) try: # 指定秒BLEのスキャンを行う scanner.scan(20) except BTLEDisconnectError as e: pass except Exception as e: logging.error("Error during scanning: %s", e) def main(): global timestamp timestamp = datetime.datetime.now().strftime("%Y/%m/%d %H:%M:00") scan("xx:xx:xx:xx:xx:x1", "名称1") scan("xx:xx:xx:xx:xx:x2", "名称2") scan("xx:xx:xx:xx:xx:x3", "名称3") if __name__ == "__main__": main()
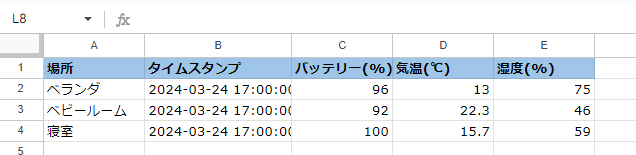
sheet1
蓄積データ。列 E,F,G はグラフ表示用に数式を設定。

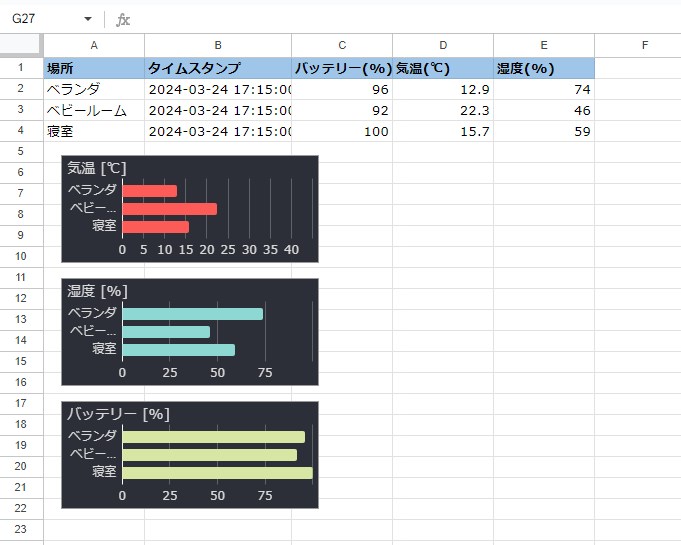
sheet2
最新データ
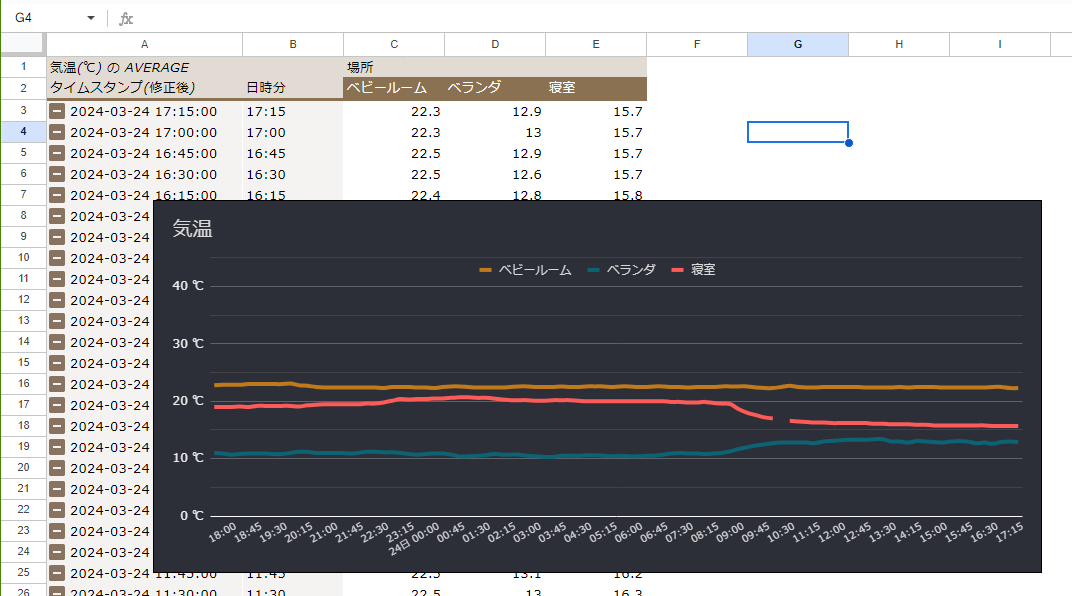
グラフの作成
蓄積データについては気温、湿度それぞれでピボットテーブルを作ってグラフを作成する。
最新データも同様。
グラフのサイズを良い感じにし、インタラクティブに公開できるので設定、iframe を取得する。
Google ChartsをQuickにStartする https://www.i-ryo.com/entry/2018/12/10/073520
「スプレッドシートのグラフは簡単に埋め込みできる」の項目を採用。
「Google ChartsをQuickにStart」の項目は、複数のチャートを表示することができず諦めた。
html の作成
取得した iframe を配置し、キャッシュなし、自動リロード設定。
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <meta http-equiv="Pragma" content="no-cache"> <meta http-equiv="Cache-Control" content="no-cache"> <meta http-equiv="refresh" content="300"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>SwitchBot Meter</title> </head> <body style="background-color:#2c2f38;"> <iframe width="299" height="106" seamless frameborder="0" scrolling="no" src="hogehoge"></iframe> ~省略~ </body> </html>
完成
